正規化は、データの重複を排除しつつ、データ更新による矛盾が発生しないようするためにテーブルを分けることです。
要は、RDBMS(リレーショナルデータベースシステム)で、「使える状態にする。そのためにテーブルを分ける」ことです。
このページでは、非正規形から第5正規形の中で主に学ぶ必要のある「第1正規化から第3正規化まで」をとりあげていきます。
また、ベテランのエンジニアとなってくると、感覚や雰囲気で「テーブルを分ける」ようになってきます。ただ、何となくテーブルを分けるのではなく、理由を持って正規化できるようになると良いでしょう。
<正規形の種類>
- 非正規形(今回の範囲)
- 第1正規形(今回の範囲)
- 第2正規形(今回の範囲)
- 第3正規形(今回の範囲)
- ボイス・コッド正規形
- 第4正規形
- 第5正規形
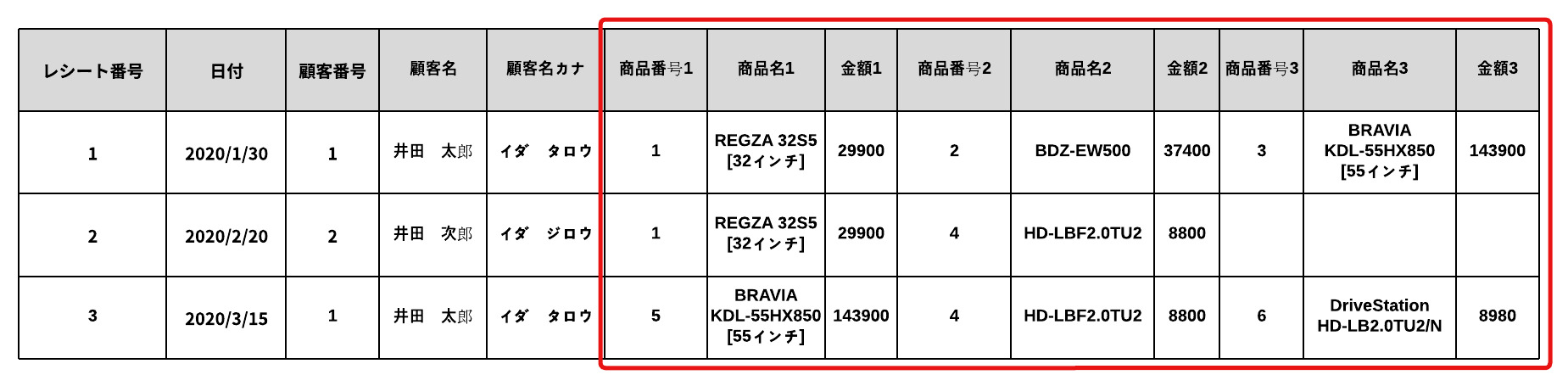
非正規形の状態は、カラム(フィールド)の値が、単一でない状態です。
下記の場合、「商品番号1」「商品番号2」「商品番号3」のように同じ属性のカラムが複数存在(重複)してしまっています。
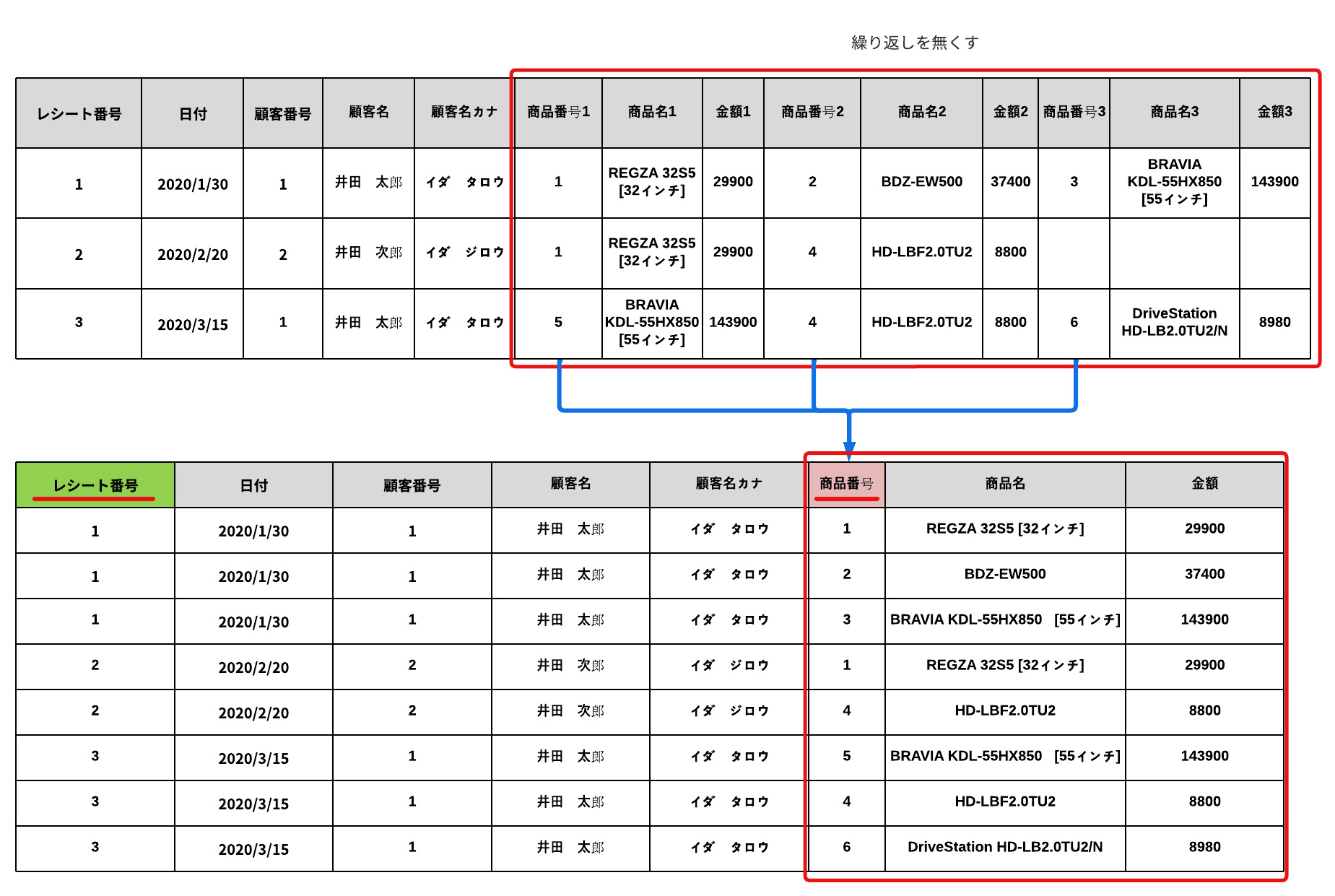
第1正規形の状態は、カラム(フィールド)の値が、単一になっている状態です。
複雑なデータ保持をしていたところを、繰り返し項目を排除してシンプルな構造に変えるだけです。
 ここでは、「主キー」になりえそうなカラム(フィールド)が2つあります。
ここでは、「主キー」になりえそうなカラム(フィールド)が2つあります。
「レシート番号」と「商品番号」です。この2つがあれば、レコードを特定することが可能です。
➡「候補キー」といいます。
第2正規形の状態は、第1正規形であり、部分関数従属性をなくした状態です。
簡単にいうと「候補キー(主キー)」に関係する非キー属性(カラム)をテーブル分離していきます。
!関数従属という言葉がポイント!
対象となるカラムから見たとき、他のカラムの値が一意に決まる関係
例えば、レシート番号で検索したときに誰がいつ購入したか(日付や顧客情報)が分かります。
このような場合、日付や顧客情報は、レシート番号に関数従属している状態といいます。
<ここで出てくるキーワード>
- 非キー属性
候補キーの一部にも含まれていない属性(カラム/フィールド)
- 部分関数従属する(部分関数従属性)
候補キーの一部が非キー属性と関連がある状態
- 完全関数従属する(完全関数従属性)
候補キーのすべてが非キー属性と関連がある状態
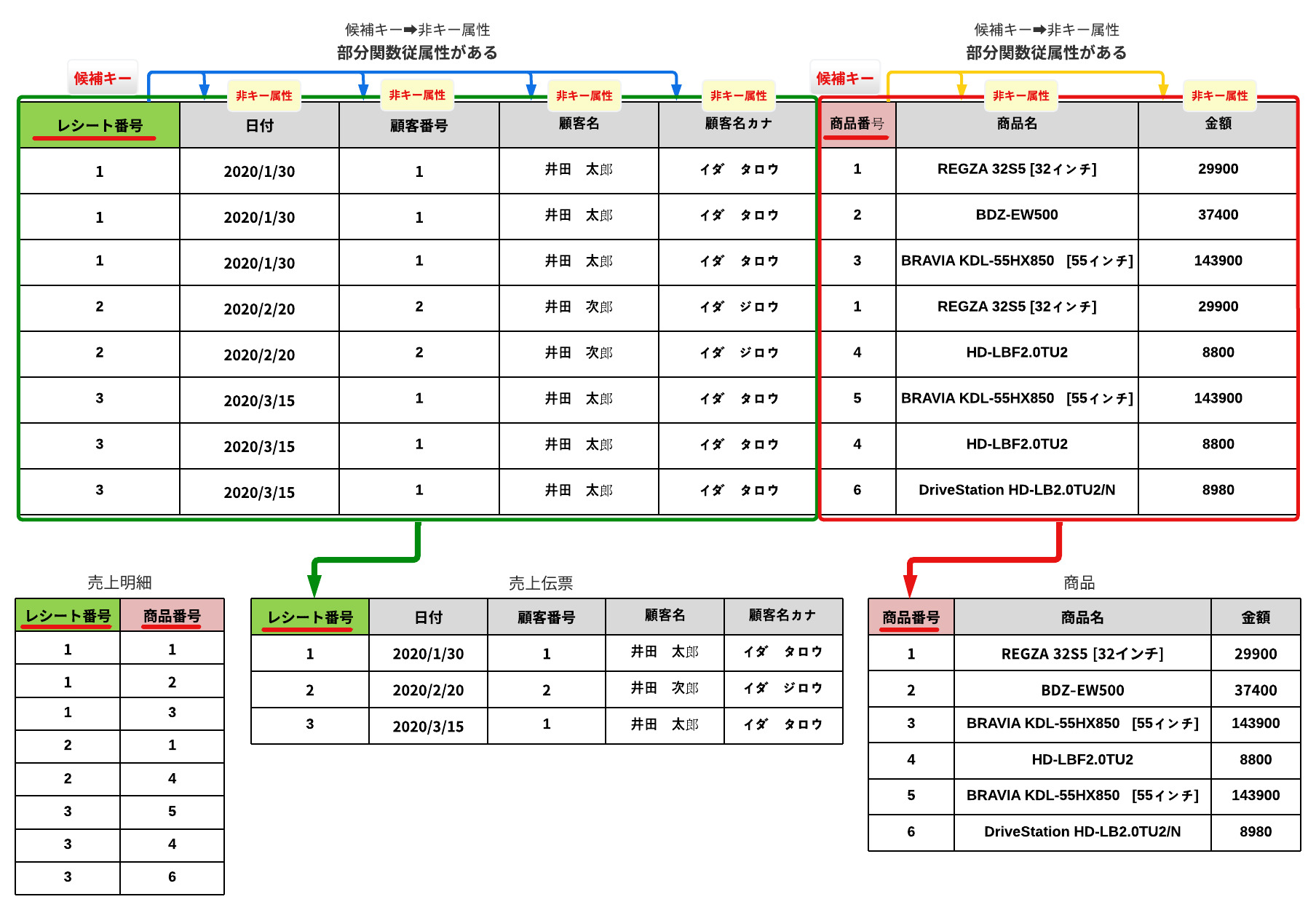
部分関数従属しているカラム
※「候補キー」が複合キーではなく、単一キーの場合には、必然的に第2正規形を満たしているため、次の第3正規化に進みます。
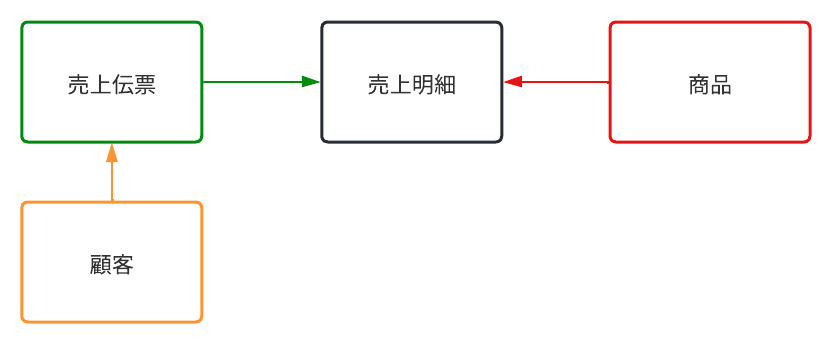
<E-R図(参考)>

第3正規形の状態は、第2正規形であり、推移関数従属性をなくした状態です。
簡単にいうと「候補キー」に関係しない非キー属性(カラム)をテーブル分離していきます。
<ここで出てくるキーワード>
- 推移関数従属する(推移関数従属性)
候補キーから、非キー属性、更に非キー属性と推移的に関係がある状態
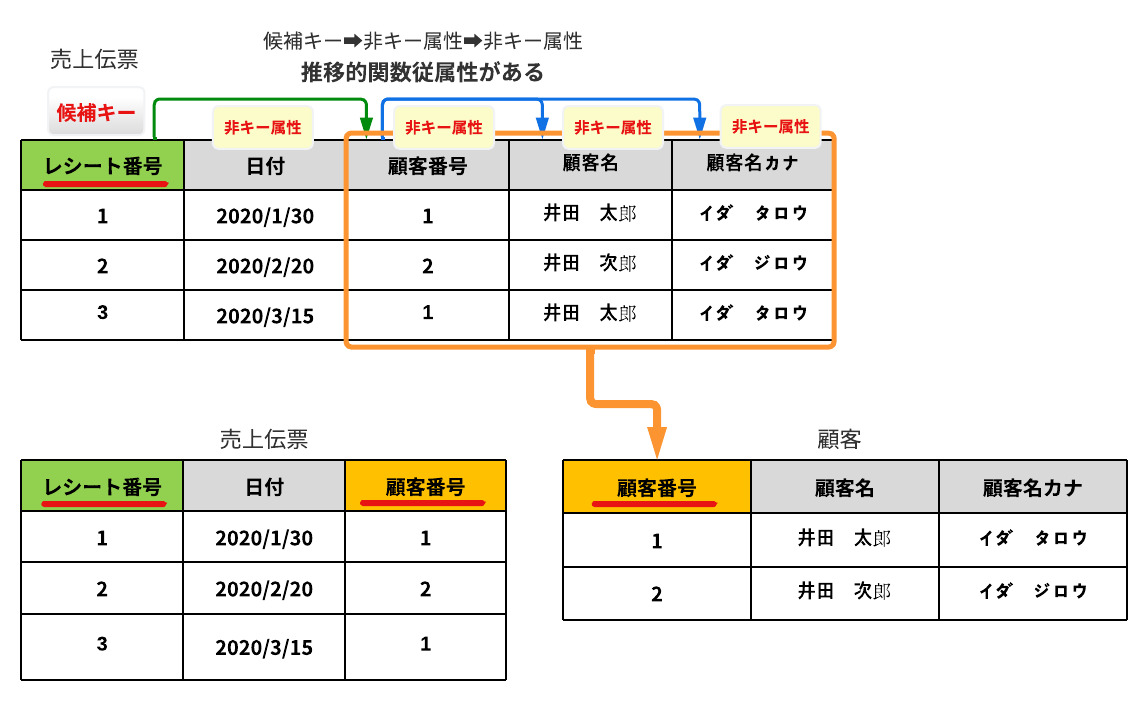
推移関数従属しているカラム
<E-R図(参考)>